Deep Dive into Google's AlloyDB Architecture for PostgreSQL

One of the more exciting announcements at Google I/O this year was the preview of AlloyDB for PostgreSQL, a fully-managed, PostgreSQL-compatible database service on Google Cloud.
The AlloyDB team made bold claims about their service:
- Compared to standard PostgreSQL, AlloyDB is more than 4x faster for transactional workloads, and up to 100x faster for analytical workloads.
- Compared to Amazon's service (they don't say but we can guess it's Aurora 🤔), AlloyDB is 2x faster for transactional workloads.
These are impressive numbers!
How were the AlloyDB developers able to achieve this kind of acceleration for both transactional and analytical workloads? What architectural innovations were necessary in order to get there? And are there lessons to be learned for architects and developers of similar cloud scale distributed systems?
In this post, I'll walk you through the architecture and design details of AlloyDB for PostgreSQL, focussing particularly on its storage engine, which is the secret sauce behind these performance numbers, and is also the catalyst for a number of administrative and management benefits of the service.
Let's begin, shall we?
AlloyDB service description and benefits
Before we go down the intriguing rabbit hole of design choices, trade-offs, and cost implications of AlloyDB's architecture, let's briefly put on our Product Management hat 🧢, to define what AlloyDB is, and to articulate how enterprises can expect to benefit from it. This will help set the context for the rest of the discussion.
First off, AlloyDB is a PostgreSQL-compatible database. In theory at least, what this means is that a customer can simply migrate data from their existing PostgreSQL database to AlloyDB, update the database connection strings in their applications to point to the AlloyDB instance, and it would all work just fine! This is good as it eases the adoption process in the customers' minds.
A quick aside:
Figure 1 shows the high level functional components of AlloyDB.
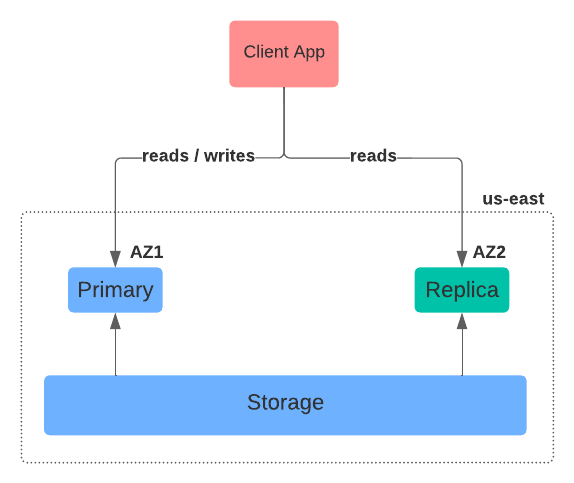
How would we describe this service?
- Firstly, AlloyDB is a regional service (think
us-east-1,us-west-1, etc. in AWS lingo), which is to say it is not multi-region. - Secondly, within a region, AlloyDB runs across multiple availability zones (AZs), or data centers, for redundancy and availability reasons. Thus, it is multi-zoned.
- Lastly, the service comprises multiple compute instances to which applications can connect. There's the singleton primary instance for servicing read and write operations. And then, there are multiple replica instances for servicing only read operations. Replica instances do not service write operations. Notably, the multi-AZ setup allows a replica to be promoted to the primary status if the existing primary instance were to die for some reason.
Also, since AlloyDB is a fully-managed service, server administration, patching, data protection, and replication are offloaded to the cloud provider.
These operational and management benefits, combined with AlloyDB's performance and scalability properties, would make AlloyDB a compelling product for enterprises that might be looking to make the move to the cloud.
With the PM-speak now out of the way, let's dive into the architectural details.
Monolithic database design limitations
Here's a question to ponder:
If you've studied the architectures of the standard PostgreSQL or MySQL databases, you'd know that their designs are monolithic in nature. What this means is that the database runs on a single node or machine, on which both compute (CPU) and storage (disks) are collocated.
Such databases have a fundamental but well-documented design issue. Due to the strong coupling between compute and storage, as data volumes increase, one cannot arbitrarily keep on adding more disks to the machine. Similarly, as the number or diversity of the workloads increase, more compute (CPUs) cannot be simply added except through a re-provisioning of the machine.
Often, the only solution is to scale-up i.e., switch up to more and more powerful machines. This is both expensive and naturally limited by the constraints imposed by Moore's Law. For these reasons, it's not common to see these monolithic designs being run at cloud-scales of either the data volumes or workloads.
Herein lies the crux of AlloyDB's innovation and architectural differentiation, and the AlloyDB team calls it Disaggregation of Compute and Storage!
Another quick aside:
What does this decoupling, or disaggregation, of compute from storage mean, and what benefits does it provide?
For database systems running business-critical transactional or analytical workloads, it's extremely important to be able to scale compute and storage independently. Not being able to do so leads to a number of operational and administrative challenges at scale:
- Compute resources cannot be tailored to dynamically adapt to the demands of diverse concurrent workloads without also impacting storage, and vice versa.
- Workloads interfere with each other when they run on such architectures, since they all vie for the same shared resources. This leads to unpredictable performance overall.
- In multi-node primary-replica setups, there's considerable lag of data replication between the primary and replica instances. Based on the database load, failover times may end up being longer than acceptable, and also less predictable.
Decoupling compute from storage solves, or mitigates, many of these limitations. It allows provisioning and scaling of compute according to each workload running in the database without impacting either the storage, or the performance of other workloads.
When needed, newer read replicas can be spun up dynamically to improve the performance of read workloads. Through efficient replication between the primary and the replicas, failover times can be improved and made more predictable.
How's all this achieved, though? The answer lies in the design of AlloyDB's storage subsystem. Let's look at that next!
AlloyDB storage layer components
Figure 2 below opens up AlloyDB's storage layer from Figure 1 to reveal its components.
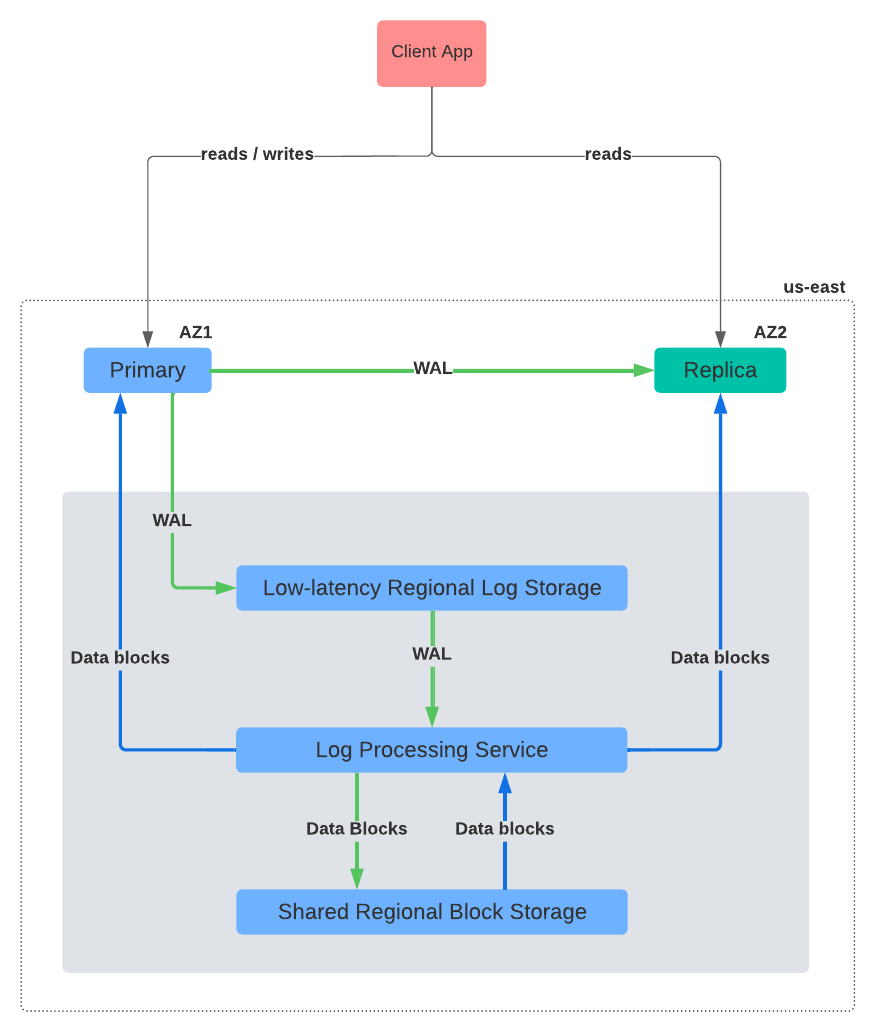
The storage layer has three major services:
- Log storage service: A low-latency service for fast writing of WAL (write-ahead log) records.
- Log processing service: Processes WAL records asynchronously to generate materialized up-to-date data blocks.
- Block storage service: Stores data blocks durably across availability zones for fault-tolerance with support for sharding.
You may be wondering what a WAL is and how it's different from data blocks. Imagine a Balances database table in a banking application. Each credit or a debit transaction on an account updates the account's balance. At the storage layer, however, data is never updated in-place due to a number of reasons pertaining to failure handling, recovery, and performance. Instead, databases will typically "write-ahead", or append, to a log file, the details of each transaction being committed.
Examples of transaction details written to the WAL include the statement type (INSERT, UPDATE, DELETE), the affected table columns, the new data values, and so on.
The WAL has an added benefit in that the database's write behavior is forced to be strictly append-only, leading to good performance at the storage layer, which is good at handling appends (also known as streaming writes) far better than random writes.
Our banking application will, thus, append a new record to the WAL for each successful credit or debit transaction. Obviously, this leads to the question, how are reads serviced? In order to keep reads snappy and fast, a process called "log replay" reconstructs the data by replaying the WAL records in chronological order, and stores them as blocks in the database.
Thus, we can think of data blocks are the most up-to-date state of the database, while a WAL is a record of all the state transitions the database has gone through.
With this context, let's now revisit each storage component's responsibilities in Figure 2:
- The log storage service is responsible for managing the WAL, and keeping writes fast and snappy.
- The log processing service is responsible for replaying the WAL records to create up-to-date snapshots of data blocks, and sending them to the block storage service. It is also responsible for serving these data blocks to the primary and replica database instances upon demand during reads.
- The block storage service is responsible for ensuring data blocks are promptly and reliably persisted locally and replicated across all zones region-wide. It also feeds the log processing service with the relevant data blocks whenever needed.
So yeah, we have decoupled compute from storage and added a ton of complexity in the process! 🤯
To what end, though? What benefits does this architecture provide?
- Due to the decoupling, the services can be scaled individually to accommodate increased demand. For example, even though the log processing service is shown as a singleton, multiple instances of it can be spun up dynamically within each availability zone to speed up WAL processing, or to serve data blocks at a higher throughput for data-intensive workloads. Similarly, the block storage service can be scaled to meet the demands of durability and reliability.
- Tasks such as data replication and data backups can be delegated completely to the storage layer without impacting the compute instances (which function purely as query optimization and execution engines).
- New replica creation and failure recovery operations are sped up because: a) the most up-to-date data blocks are already available (having been reconstructed from the WAL), and b) data blocks can be read from any of the availability zones, no matter whether it's an infrastructure failure, or a zone failure.
AlloyDB writes processing
We'll now do another double-click of AlloyDB's architecture to examine how it handles writes.
Figure 3 is essentially a reproduction of Figure 2 with the read paths removed so that we can just focus on the write paths.
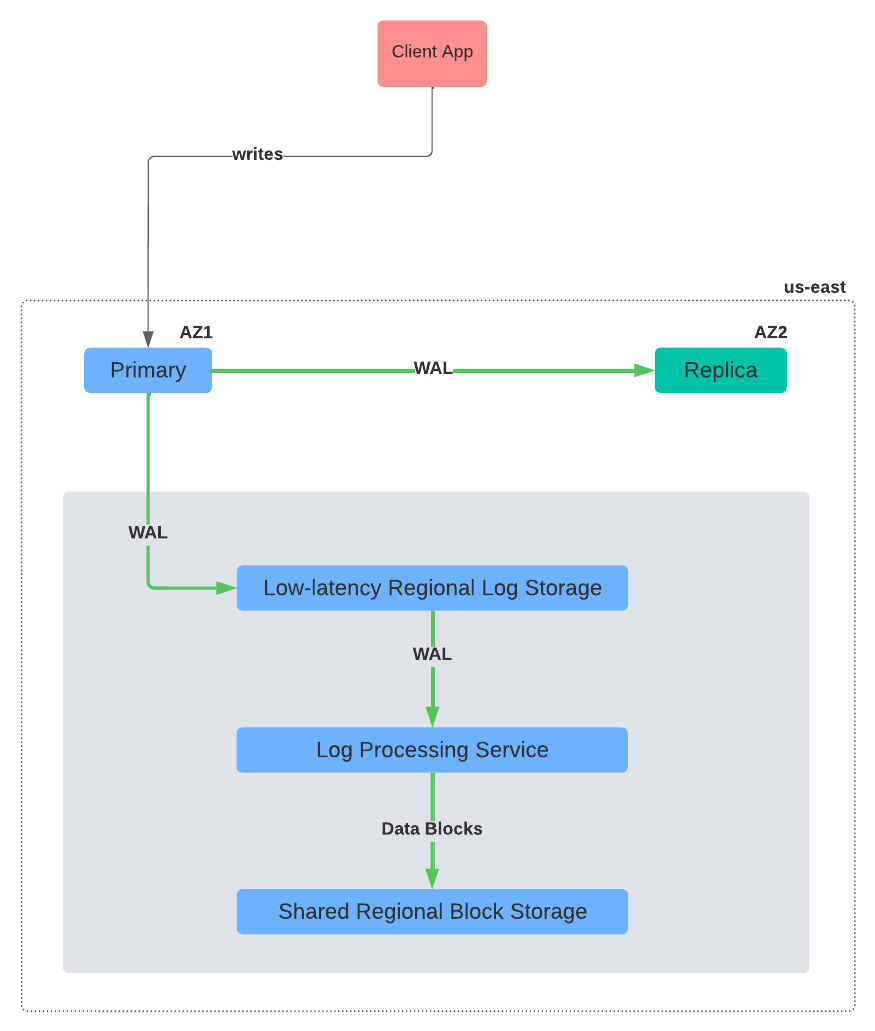
When a client application wants to issue a write, such as an INSERT, UPDATE, or DELETE statement, it must always do so against the primary instance since replica instances only serve reads.
When the primary instance receives a write, it appends a new record to the WAL upon successful execution of the statement and a transaction commit (as I explained before). As soon as the log storage service acknowledges that the WAL records has been durably persisted, the primary instance responds to the client application to indicate its write was successful.
Simultaneously, the primary instance also transmits the WAL record to all active replicas so that they can update their respective internal states. This is a critical step in the write workflow, as otherwise the replicas could quickly go out of sync from the primary, and start serving stale data to clients.
Asynchronously, the log processing service consumes the newly written WAL records, replays them on the current state of the relvant data blocks, and persists them to the underlying storage service.
Of course, there are a number of gory implementation details relating to MVCC and ACID semantics. Still, this would be a fair and accurate high-level representation of what goes on under the hood for processing writes.
AlloyDB reads processing
Next, we'll look at how AlloyDB's architecture processes reads.
Figure 4 below shows the data paths for reads similar to how Figure 3 above showed the paths for writes exclusively.
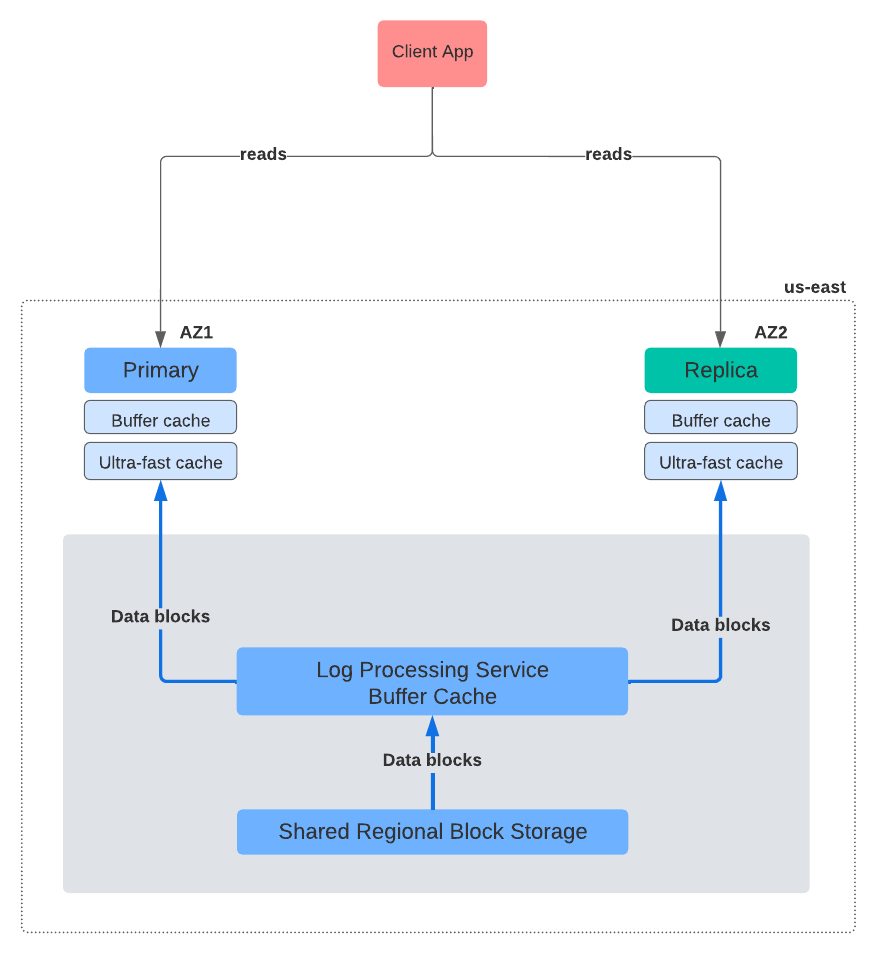
Unlike for writes, the client application is free to connect to any of the instances to issue a read operation (a SELECT statement, for example). Somewhat surprisingly, though, the processing for reads is far more involved than that for writes.
By the way, all this time, when we were extolling the virtues of decoupling compute from storage, we didn't bring up an obvious but undesirable side-effect of it. When compute and storage are decoupled, the read and write throughputs suffer, due to additional network hops, transport protocol overheads, and such, between the compute and storage services.
In order to compensate for these new overheads, all architectures built on the notion of compute-storage decoupling resort to aggressive caching strategies, sometimes at multiple layers, to improve read performance.
AlloyDB is no different! As seen in Figure 4, in addition to the database's own buffer cache, the AlloyDB architects have added what they call an "ultra-fast cache" to the compute instances. This is in order to both extend the working set size, and mitigate any slowdown due to network roundtrips due to missing data blocks.
Also noteworthy is the fact that the missing data blocks are fetched from the log processing service, and not the block storage service. The log processing service, in addition to having the ability to process the WAL also supports PostgreSQL's buffer cache interface. It does this in order to cache data blocks from the block storage service, and serve them to the primary and replica instances. The log processing service, thus, effectively becomes another caching layer in the architecture.
To draw a very rough analogy (due apologies to the purists 😜) with microprocessor caches:
- Think of the buffer cache in the primary / replica instances as the L1 cache
- Think of the ultra-fast cache as the L2 cache
- Think of the log processing service buffer cache as the L3 cache
See what I mean?
As you must be rightly thinking, this would have a considerable effect on the provisioning and operating costs! Enterprises, though, who are looking to move to the cloud for its benefits, would likely not mind paying up!
So, we've looked at AlloyDB's architecture to understand how it disaggregates / decouples compute isntances from the storage layer, and how it processes reads and writes. We examined the design choices that were made to ensure reads and writes remain highly performant despite the decoupled architecture. AlloyDB uses caching generously, which explains the impressive performance numbers for both transactional and analytical workloads, compared to standard PostgreSQL and Amazon's Aurora.
AlloyDB seems very well designed, and I like it a lot! Congratulations to their engineering team! Do check the service out on Google Cloud!
References
- Introducing AlloyDB for PostgreSQL: Free yourself from expensive, legacy databases
- AlloyDB for PostgreSQL under the hood: Intelligent, database-aware storage
Hope you enjoyed reading this!
Subscribe to my Data Management Newsletter for more original content on databases, data management and data protection!





Member discussion