Newsletter #3: Time-series databases, graph databases, Kafka

Welcome to Data Management Newsletter #3, where I curate interesting articles on data management and data protection for data practitioners and executives. This week's themes are time-series databases, graph databases, and Kafka.

Time-series Databases & Kafka
Kafka Summit London 2022 just wrapped up this week, so I'll dig around for interesting talks to share over the coming weeks. In the meantime, take a look at this short presentation by @russellsavage from last year's summit, titled Kafka & InfluxDB: BFFs for Enterprise Data Applications.
InfluxDB is an open-source time series database, similar to Prometheus, and is typically used to store metrics data generated from sensors, infrastructure, and applications. The presentation above talks about how robust real-time data pipelines can be built by combining InfluxDB with Kafka.
Though the focus in the presentation is on InfluxDB, the general architectural pattern seems to be the following:
- Time-series databases are good at ingesting, storing and analyzing metrics data in real-time.
- However, reliable delivery of the data in the ingest path (if one cares about that sort of a thing) cannot be easily guaranteed without over-engineering the pipeline.
- Throwing in a message broker like Kafka into the mix allows data to be staged before being ingested into the time-series database.
Kafka provides scale, durability, and fault-tolerance, and allows for an architecture with a clean separation of concerns.
In the case of InfluxDB, integration with Kafka is achieved using the Telegraf agent, which can act as both a Kafka producer and consumer as the picture below illustrates.
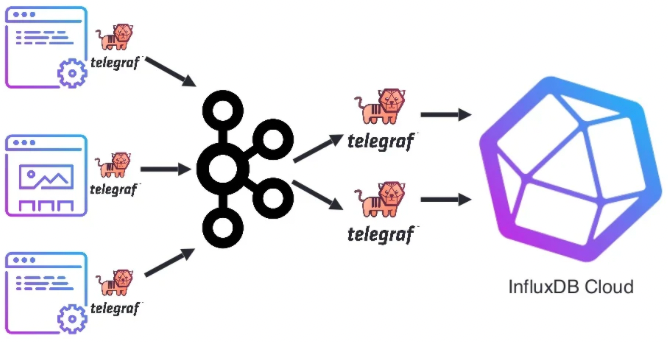
Additional reading
- Charles Mahler writes about a similar use case in How Companies Are Using InfluxDB and Kafka in Production.
Graph Databases
Graph databases, such as Neo4j, Amazon Neptune, and Oracle's Graph, model data as nodes, edges, and properties / attributes, unlike relational databases which model data using primary key / foreign key relationships.
@neelimatd talks about an interesting application of graph databases in A Brilliant Use for Graph Databases: Mapping Legacy Software.
In re-architecting an old monolithic legacy application, how does one easily identify its component modules, and the inter-dependencies among them?
This requires both deep domain knowledge from module owners and experts, and good documentation, which is often inadequate, incomplete, or stale. It's why teams often struggle with modernizing their old legacy applications!
Oracle's Graph helps simplify this process using a concept called Bounded Context, which is a self-contained independent module of the application (similar to a service in a Service Mesh). For example, in an e-commerce application, Order Management and Payment Processing might are their own independent modules (hence, bounded contexts).
Graph has pre-built algorithms that use historical data about monolithic applications collected over 30-40 years to identify bounded contexts in complex monolithic applications. It then helps visualize and analyzer the inter-dependencies and relationships among the bounded contexts, thus saving teams valuable time in the first step of modernizing their application.
Frankly, all this sounds a little too good to be true! Check it out, though, as it's an interesting idea.
Additional reading:
- The extended article, Graphs simplify software development, talks about two other use cases of Oracle's Graph – Software testing, and Identifying business processes in an application – in addition to Identifying Bounded Context.
That’s all for this edition of Data Watcher. Hope you enjoy reading the linked articles!
Huge shoutout to the folks at @InfluxDB and @Oracle for the content!
Cheers, and hope you're having a great weekend!





Member discussion