Demystifying Data Mesh: Part 1

Data management products and architectures such as Data Lakehouse, Data Mesh, and Data Fabric hold great interest for organizations that are looking to become more data-driven in search of better ways to harvest their data, gain insights from it, and provide better experiences to their customers.
Among these, Data Lakehouse seems the most well-understood, primarily because vendors like Snowflake and Databricks have done a good job of evangelizing the idea through their products.
Data Mesh and Data Fabric, on the other hand, are still relatively abstract at this time. There aren’t any concrete products or reference implementations one can play with in order to better understand them. Invariably, discussions around these come across as ambiguous and hand-wavy, as the following remark I recently overheard a Chief Data Officer make illustrates:
🤯 … the data mesh is a frame of mind …
But, of course, it’s much more than that!
In this two part series, I’ll explain what Data Mesh is, what problems it solves, and how to implement it for your organization. This is the first post in the series and will focus on the clarifying the specific problem Data Mesh aspires to solve. The next one will delve into the architectural and operational aspects of implementing it.
So, let’s begin… but first, let’s talk about data silos!
Data silos are pockets of data that get created in an organization over time as a result of teams working independently of each other. They often get a bad rap, but as experienced practitioners know, they’re inevitable at scale, and even desirable for agile data-driven organizations, as they enable teams to become more specialized and achieve greater independence in terms of release management.
Often, silos are cited as the reason that Data Mesh is needed. While true, this doesn’t precisely articulate what problem Data Mesh solves and how it will benefit organizations.
In order to understand Data Mesh, it’s essential to understand a related yet very different problem within data engineering, called data integration. The challenges associated with data integration are what a good Data Mesh implementation will simplify, in turn allowing teams to be more agile and data-driven.
We’ll cover these challenges below but as you read along, remember this:
Okay — but what exactly is data integration?
Let’s make this discussion more concrete!
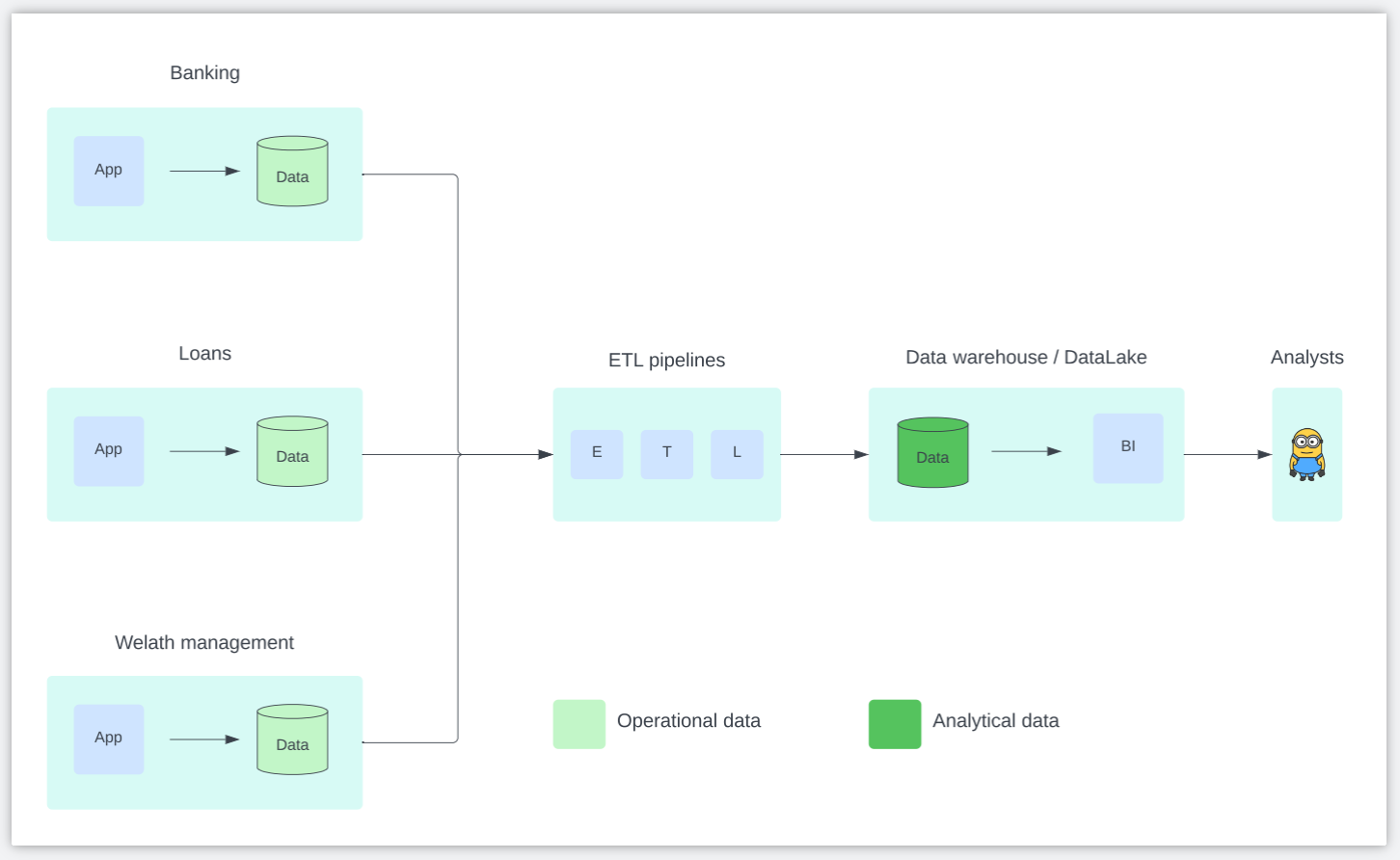
Consider a financial services organization that offers retail banking, personal and mortgage loans, and wealth management services to its customers. The picture below shows a rather simplified version of the silos along with the relevant data flows, and the teams that produce or consume the data.
Quick aside:
🤔 Simplicity aside, what’s wrong with the picture?
We’ll come back to this in a bit but let’s call out a few things first:
- Notice how silos can be both natural and necessary — natural because each financial service offering would have come into existence at a different time, and necessary because it allows each individual team comprising data owners, product owners, and developers to be specialized for their respective business domains.
- Service owners (Banking, Loans, Wealth Management) typically are data producers. Their data is typically operational in nature with little to no global context outside their domain.
- Analyst teams (Data Scientists, Data Analysts, Marketing), on the other hand, are data consumers. Their data is highly analytical in nature with ample global context to seam the individual silos together for making meaningful business decisions.
- A network of ETL pipelines, owned by a data engineering team, is responsible for cleansing, annotating, and transforming the silo-specific operational data into analytical data.
Given this data architecture, what kind of insights might an analyst be interested in? Here are a couple (admittedly trivial but illustrative in this context):
- Find individuals with high savings account balances to upsell wealth management.
- Find individuals with a high net worth to offer cheap personal loans on margin.
Notice how answering these queries requires stitching together (joining) context from multiple silos. This is what data integration accomplishes — identifying common business semantics among different silos, unifying them in meaningful ways, and presenting a holistic view of data for business intelligence and insights.
This transformation of operational data into analytical data occurs as part of ETL processes, and is one of the harder problems within data engineering. Often, silos will use different names for the same business entities — customer names may be called name, fullname, or custname. Sometimes, different data types are used to encode the same entity — ages may be stored as integers, or strings.
Getting these transformations right at scale requires both silo-specific business domain knowledge as well as coordination among data owners across silos. Data engineering teams often become a bottleneck because of this highly centralized operational model. Every change to a silo’s data model has the potential to break data integration processes across the organization. In the absence of coordination, data engineering teams are naturally reactive in responding to such breaking changes, which disrupts the flow of data to the business consumers, worsens the quality of insights that may be derived from it, and increases uncertainty about business outcomes.
Now going back to the picture above, we can see more clearly what’s wrong with it — it’s the carving out of data engineering teams as a separate, centralized entity, distinct from and agnostic to the business domains (silos), whose data they’re supposed to “engineer” and “integrate”!
Summarized another way, using the monolith analogy from the Service Mesh world:
This👆is the precise problem statement that is driving organizations to explore and rearchitect their data infrastructure using Data Mesh principles.
The promise of Data Mesh is that it will do for data what Service Mesh did for applications — breaking up monoliths into smaller, more manageable, and more agile components that hide complexity and change, and communicate with each other using API-driven abstractions.
Data Mesh takes a decentralized, bottom-up approach to the sharing of data between producers and consumers. Data that used to typically live at the far reaches of a silo’s application stack is now pulled up, and put front and center (think Data-as-a-Product) for consumers to consume using their preferred tools of choice. Data integration becomes a shared responsibility among data owners and they are incentivized to cooperate with each other in order to generate high quality data abstractions for the business users to consume.
How does it all come together, though? What does a practical implementation look like? What operational and personnel changes does it entail?
We’ll explore these in more detail in the next post, both from a technology as well as a business operational perspective. In the meantime, hopefully this post was able to articulate the fundamental problem that Data Mesh is meant to solve, and what it promises for large data-driven organizations operating at scale.
I look forward to sharing the follow-up post with you soon!
Cheers!
Hope you enjoyed reading this!
Subscribe to my Data Management Newsletter for more original content on databases, data management and data protection!





Member discussion